
Addressing Scale with Functional Services
Brandfolder, Inc. is a growth stage Software as a Service company headquartered in Denver, Colorado. Brandfolder provides a digital asset management solution, helping businesses store, organize, manage, create, distribute, optimize, and analyze their digital assets more effectively.
In addition to our projected growth forecast, we’ve also struck an incredible partnership with GettyImages! This has accelerated our need to focus on the performance of critical steps of our ingest pipeline, notably moving files and readying them for end-user consumption. To establish internally acceptable performance metrics we set up ingestion-related Service Level Objectives (SLOs); this surfaced a series of challenges in our existing system architecture.
Ultimately, as users are creating and consuming assets within Brandfolder to power their ecommerce experience, marketing emails, or distribute live-event content we set a high bar for timings of attachments reaching their fully processed state. See how companies are using assets in Brandfolder as their source-of-truth, https://brandfolder.com/client-stories/spyderco.
We’ll discuss the opportunity, challenges, requirements, and architecture of service growth within the context of Brandfolder Engineering. Additionally, as we’ve seen the outcomes of this approach, we will reflect on the experienced benefits to-date as well as some outstanding challenges and hopes for improvement in the managed services and tooling.
Challenges
As startup tech companies embrace the idea of buying before building, we at Brandfolder have gotten where we are today with the support of our partners. Naturally though, growth provides reason and opportunity to take on more of the build and management burden where service providers and partners might not suffice as operational demands increase.
Our core functions that fit into this category, given we’re a digital asset management product, has us focused on files. Listed are a few contributing factors that have influenced us moving from SaaS providers to custom built:
- Cost ($/asset)
- API rate limits
- Opaque queue depths
- Inconsistent task enqueue-to-completion timings
Essentially, we’ve seen that while price might scale linearly we can scale that price non-linearly in-house which proves advantageous over a certain volume. Additionally, the lack of visibility into partner systems and the inability to adjust to the needs of our users results in our system not meeting our internal performance expectations. Finally, given we have well established interfaces with external partners and a system leaning on their capabilities, it provides a great set of requirements when the time comes to move in-house.
Requirements
In effort to build something future-proof, we’ve added a few requirements beyond the interface and capabilities of our existing partner integrations.
- Managed Infrastructure. While we embrace a number of self-managed services internally, the current state of cloud computing has plenty of options for managed infrastructure, such that we can switch to something in-house without taking on the entire operational burden.
- Autoscaling capabilities. Naturally, in a cloud-native environment ingestion-related capacity for a company dealing with files needs to autoscale.
- Long request duration timeouts. With files being indefinitely large and always growing, we need to have sufficient time to perform our functionality without the request being terminated.
- Non-interrupting deploy events. Requests in-process during a deploy should ideally be allowed to finish. This allows us to deploy at high frequency as we are accustomed to without impacting overall execution throughput.
- Custom runtime configuration. The ecosystem for file-related tooling is broad and well established, we’ll be positioned well if we can completely configure our own containers.
Fortunately the state of modern software has plenty of technologies to address these requirements. We set a high standard for uptime, and work with our team and partners to make sure we are exceeding not only our committed SLAs but fulfilling our internal SLOs.
Google Cloud
We’re happy customers and proud users of Google Cloud: https://cloud.google.com/customers/brandfolder. Within the Google Cloud Platform, we have numerous tools to help us build for these stated requirements, and options with varying degrees of customization and configuration. Here we’ll discuss a few of the primary options:
Google Compute Engine - Standard cloud computing, while we use GCE for other infrastructure components, there would be significant work required to meet the stated needs.
Google Kubernetes Engine - An incredible managed Kubernetes environment, while we are already leveraging GKE within our infrastructure, we ultimately decided that our first releases of these services would take a bit more configuration in GKE than we could get out of the box from other solutions.
Serverless options (more detail in the GCP matrix https://cloud.google.com/serverless-options)
Google AppEngine - One of Google’s “serverless” offerings. Standard environment does not allow for custom containers, and has a 1minute request timeout. The Flexible environment looks interesting,
Google Cloud Functions - “serverless” in the most traditional sense, function as a service. Standard runtimes by language with no customization and no support for concurrency.
Google Cloud Run - The latest in Google’s “serverless” offerings, an environment that came out of the KNative project. It supports deploying revisions and routing novel requests to new revisions without destroying containers finishing requests.
We were pretty excited at the ease of Google Cloud Run, being able to run custom docker containers, the release process, autoscaling capabilities, and the 15 minute timeout. Ultimately this is the direction we decided to go, and have had a great experience.
Architecture
The components in play are:
- Google Cloud Run as the HTTP interface with
/work/asyncand/workendpoints - Google Cloud Tasks as the queuing mechanism for work
- Golang as the runtime given it’s efficiency streaming bytes, operational efficiency, and the ability to deploy tiny containers containing just an executable binary
- Protobuf as the message schema and serialization (on the queue, JSON conversion used at the service-boundary), see the base of our rpc messages
syntax = "proto3";
package bf_protos;
message SvcWorkRequest {
string sourceFile = 1;
string webhookUrl = 2;
FileMetadata fileMetadata = 3;
Context context = 4;
}
message SvcWorkResponse {
...
Context context = 2;
Error error = 3;
}
message FileMetadata {
string mimetype = 1;
string md5 = 2;
int64 size = 3;
}
message Error {
string type = 1;
string message = 2;
}
Specifics of the interaction between the components are details in the sequence diagram
One cool aspect of this system is that Cloud Tasks is actually sending our webhook responses to clients, since it simply needs an HTTP target which has relieved the need for yet another component to the system to attempt http requests for webhooks.
This architecture allows us to validate the incoming request efficiently, drop it into a queue, and process at whatever throughput cloud run will let us.
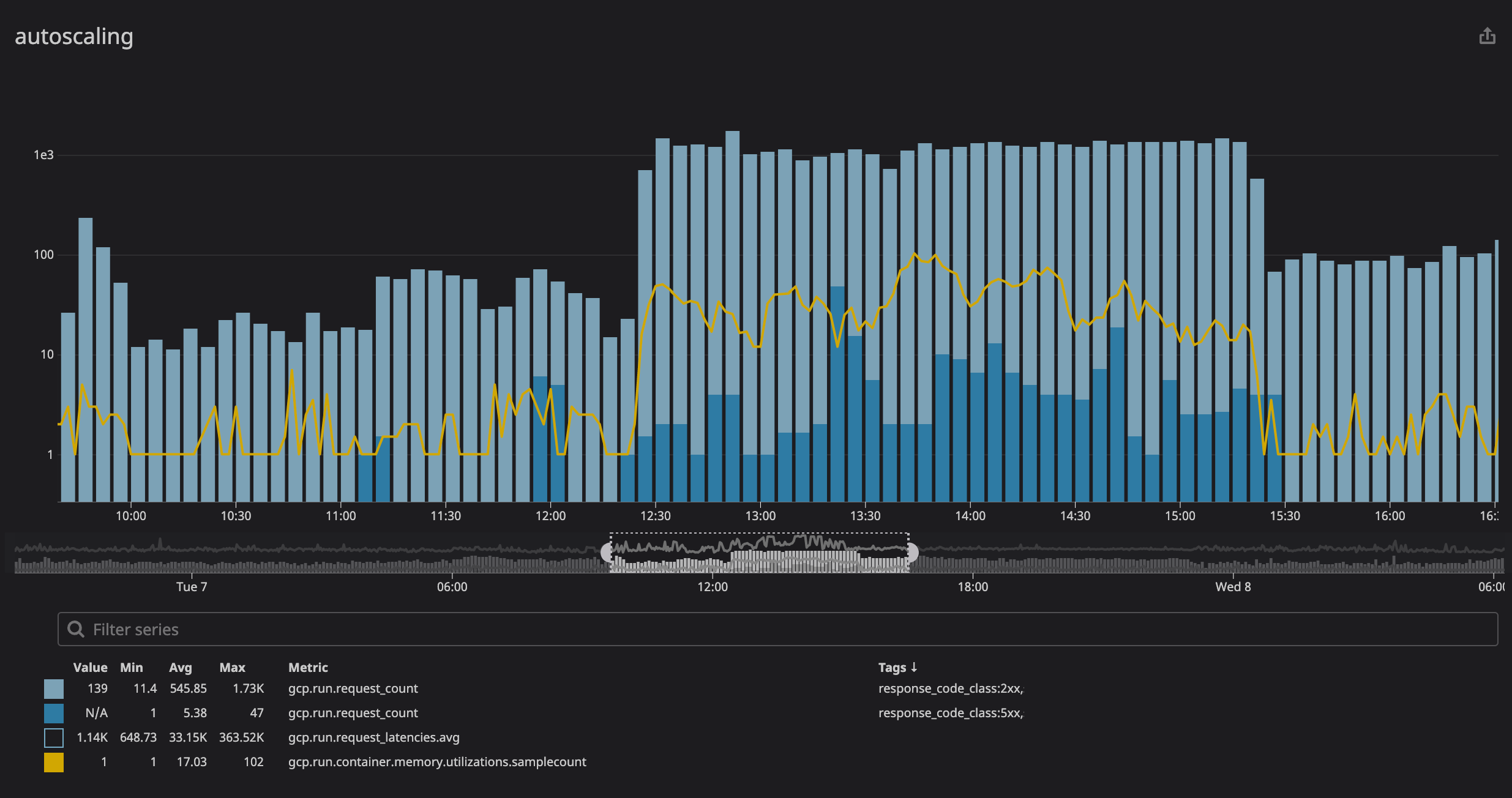
Note that the relatively small deployed images (10.78 MB) certainly contribute to the speed at which the service autoscales.
Benefits
All-in-all our move to using this Cloud Run with Cloud Tasks for autoscaling functional services within the Brandfolder infrastructure has been a resounding success! Let’s look at some of the highlights:
Hands-off Infrastructure has given us >6months of incredible performance with no downtime and beyond minor logic changes for new use cases, no maintenance required.
Sandboxing improves Security and our system posture as it pertains to image data related vulnerabilities. Given that we are dealing with files, the serverless environment gives us a nice sandbox in the event we are leveraging memory-unsafe tolling while processing our images.
Hands-off autoscaling means that we have not needed to define scaling triggers or metrics, Cloud Tasks in conjunction with Cloud Run leverages latencies, HTTP status codes, and retries to manage scaling.
Configurable Scaling Limiters came in very handy within Cloud Tasks in the Notifier Queue, as the clients are not always capable of autoscaling themselves we leverage the “Maximum Concurrent” setting to protect our clients and webhook receiving server capacity.
Operational Efficiency is apparent when we look at the concurrency capabilities of our golang application and the resulting cost savings. Not only is the Cloud Run cost model improved over “Cloud Functions” due to this concurrency, but Cloud Run cost is based on active execution times versus container lifespan like traditional VMs. For some of these functions we saw this change in the execution cost:
- SaaS provider - approximately 300 executions per dollar
- In-house app - approximately 60000 executions per dollar
Finally, with the GCP integration in Datadog we are able to see metrics from Cloud Run and Cloud Tasks along all of our other infrastructure. We’ve also been able to configure alerts such as on the queue/task_attempt_delays timings.
The following dashboard displayed is from our dev environment during a test scenario
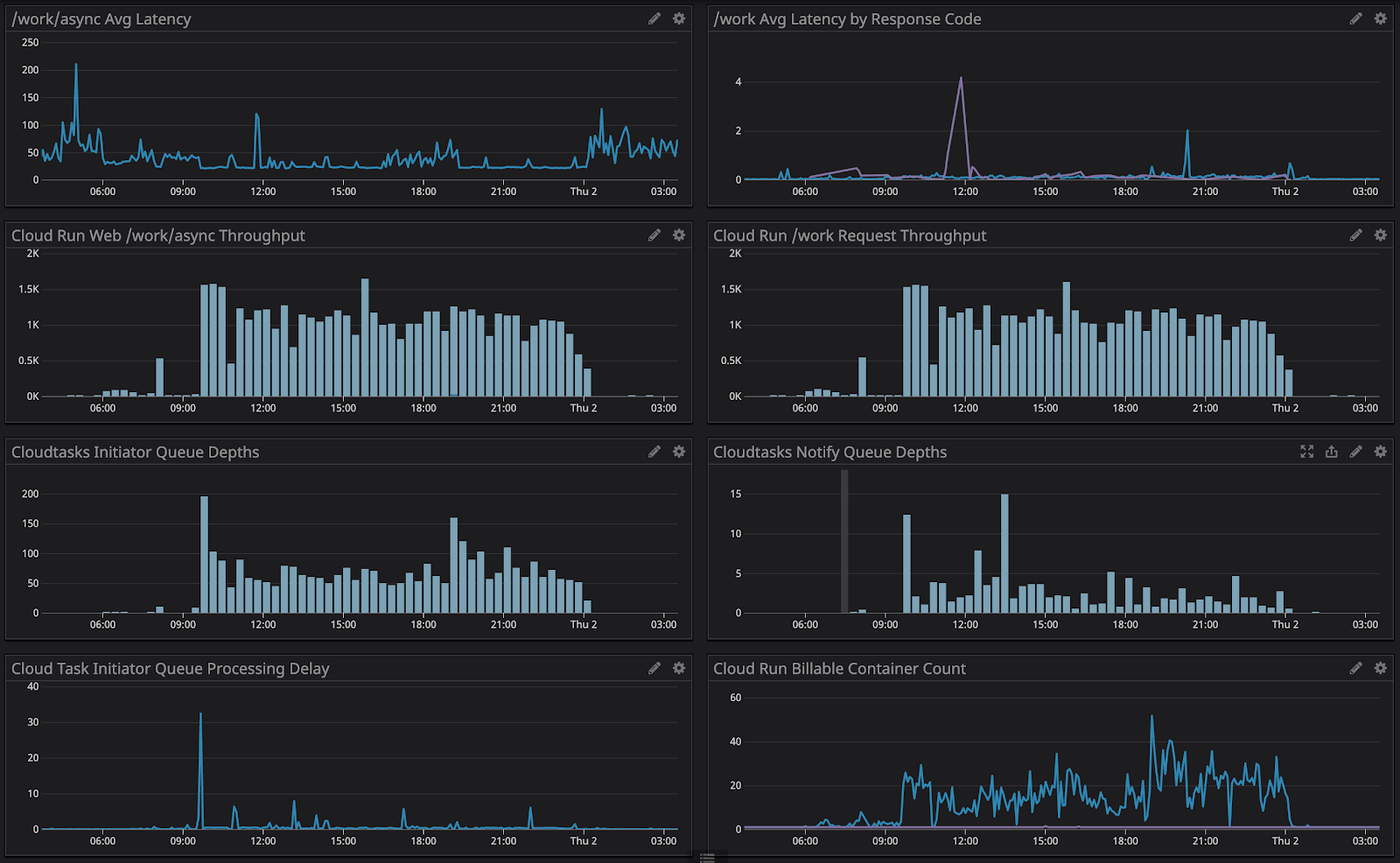
Note the nearly instant scaling-up and the immediate throughput as a response to queue depth.
Challenges
While we’ve been overwhelmingly pleased with the results, there have been some nuances within our infrastructure and specifically some feedback for our partners at Google.
Infrastructure Configuration
From a configuration perspective, we generally leverage Terraform to manage our configuration. At the time of venturing into these services all of the componentry was not configurable via terraform (although now terraform has a module for google_cloud_run_service). The current state of configuration is a bit split where we have configuration in: Terraform, CircleCI ENV/context, and CircleCI config.yml to provide configuration to the gcloud cli and system. Leveraging the google_cloud_run_service provider in Terraform should allow us to focus more on service account permissions for deployment in CircleCI and configuration in Terraform. But this is one of the nuances that comes with managed services, their integration with terraform and Infrastructure as Code.
Cloud Tasks
Cloud Tasks has a few nuances itself, notably a task’s awareness of it’s MAX_ATTEMPTS and the native throttling behavior. Discussing MAX_ATTEMPTS, the configuration is applied to the queue itself, but the actual worker process behind the queue is unaware of MAX_ATTEMPTS, only it’s X-CloudTasks-TaskExecutionCount. This required us to coordinate MAX_ATTEMPTS and TaskExecutionCount to appropriately notify (the client) when retries have been exhausted.
func areRetriesExhausted(req *http.Request) bool {
retries := req.Header.Get(retryCountHeader)
if retries != "" {
r, err := strconv.ParseInt(retries, 10, 32)
if err != nil {
log.Printf("Failed to parse header value %s to an int: %v", retries, err)
return false
}
return r >= maxRetryCount
}
return false
}
The issue we’ve experienced specific to the documented behavior of Cloud Tasks is the lack of override when the system is experiencing an elevated error-rate. In the event there are many bad tasks in the queue, it can negatively impact the throughput of “good tasks” without recourse to force them through the system. Resolution on this topic could certainly be achieved by segregating our queues further.
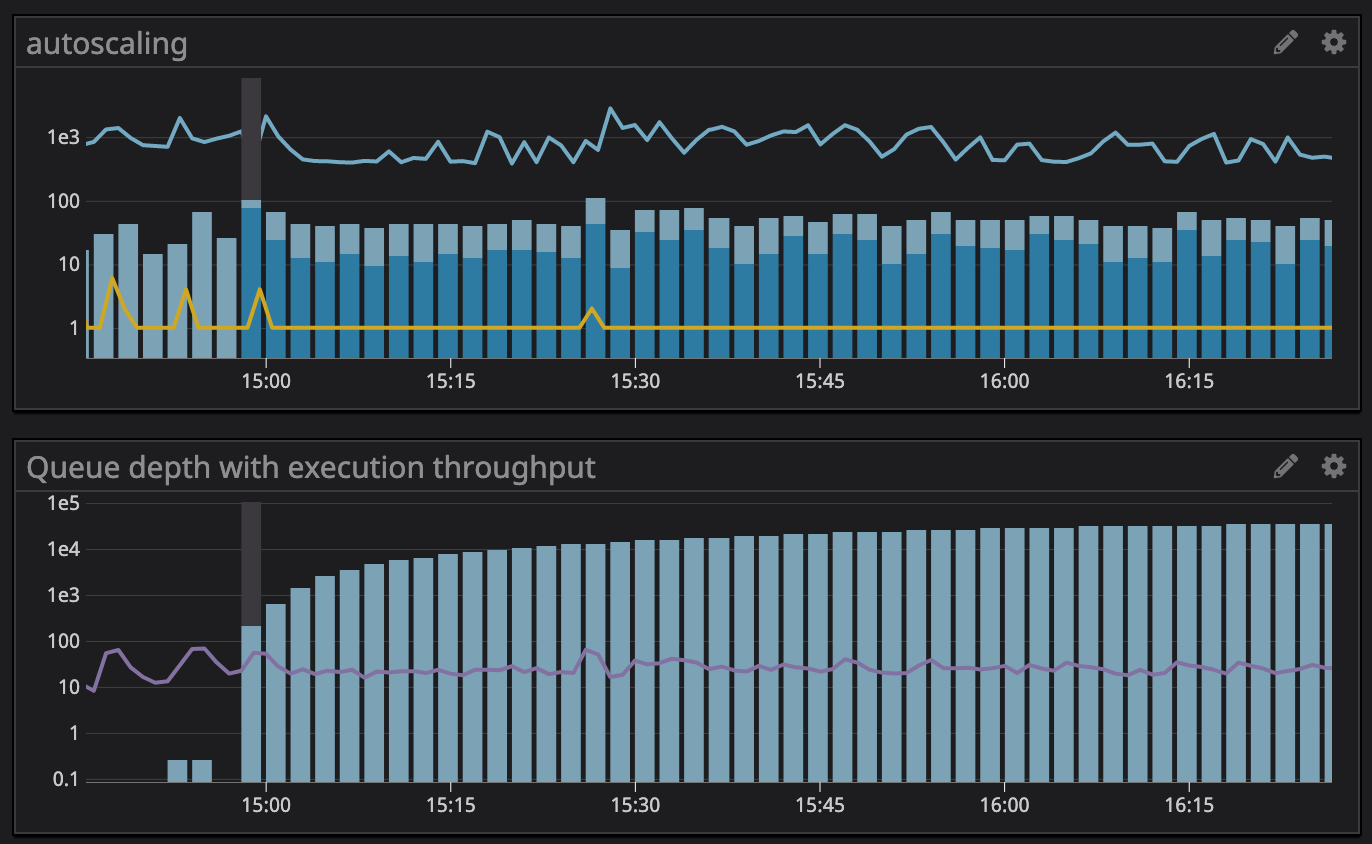
See how the queue depth grows, but there is no autoscaling nor increase in throughput. This is driven by the intelligent request rates coming from Cloud Tasks, where is’t seeing a significant number of 5xx responses (presence of dark blue bars on the top bar chart) and the result is a constant [slow] stream of requests until the executing recovers.
Telemetry
Finally, while the exposition of metrics from GCP to be consumed through our Datadog account’s integration provides us the ability to construct dashboards, there’s a significant gap between the metrics an operator would hope to see and what in reality is available (either within Datadog or GCP console). Some metrics that could be created or exposed to integrations:
- Container-level CPU and Memory utilization is missing. The existing metrics don’t provide an adequate picture of the efficiency or memory footprint of containers executing work (a notable difference from cloud functions is the innate concurrency in cloud run). We spoke with the Serverless product team a bit on this topic and it was acknowledged, so we’re hopeful to see greater visibility into container-level metrics in the future.
- Instance count metrics are a bit convoluted. We appreciate the pricing model by-which billing applies only to containers receiving active requests, but as a result of only having billing metrics exposed we don’t have great visibility into our overall container footprint especially as it relates to autoscaling configuration of max instances.
- Function-level percentiles are not available outside of GCP. While having a measure of “avg_latency” is advantageous, we are itching for percentile metrics to be exposed to integrators, i.e. p90/p95/p99 stats on our services. This applies to a number of time-based metrics from cloud run as well as cloud tasks.