Introduction
Enabling a data driven creative experience for our (Brandfolder’s) customers involved augmenting an extremely good product by building a machine learning platform to seamlessly deliver the data suite of products. Working within the constraints of being a very small team operating on a small budget and short timeline, it was important to leverage open source projects (Apache Spark¹, Apache Zeppelin and Databricks mlflow²) and cloud services (Google Cloud Platform — GCP³) to put together the architectural puzzle that starts with ingestion of raw application and event data on one end, and outputs a Machine Learning (ML) service on the other. In the following a description of this ML architecture, the reasonings behind the choices and the learnings thereof are described. As our services were hosted already on Google Cloud Platform (GCP) and more importantly their suite of services, IAM and security hooks were well suited for our needs, we decided to build the entire ML platform on GCP. This involved using the following GCP services: CloudSQL(a Postgres replica database (DB) of the production Postgres application DB), Cloud Storage (as the data lake), Dataproc (as the HDFS computing cluster), Composer (as the batch job scheduler), Pub-Sub (as the backbone data pipeline), Container Registry (to store docker images) and Kubernetes Engine (as the container orchestrator).
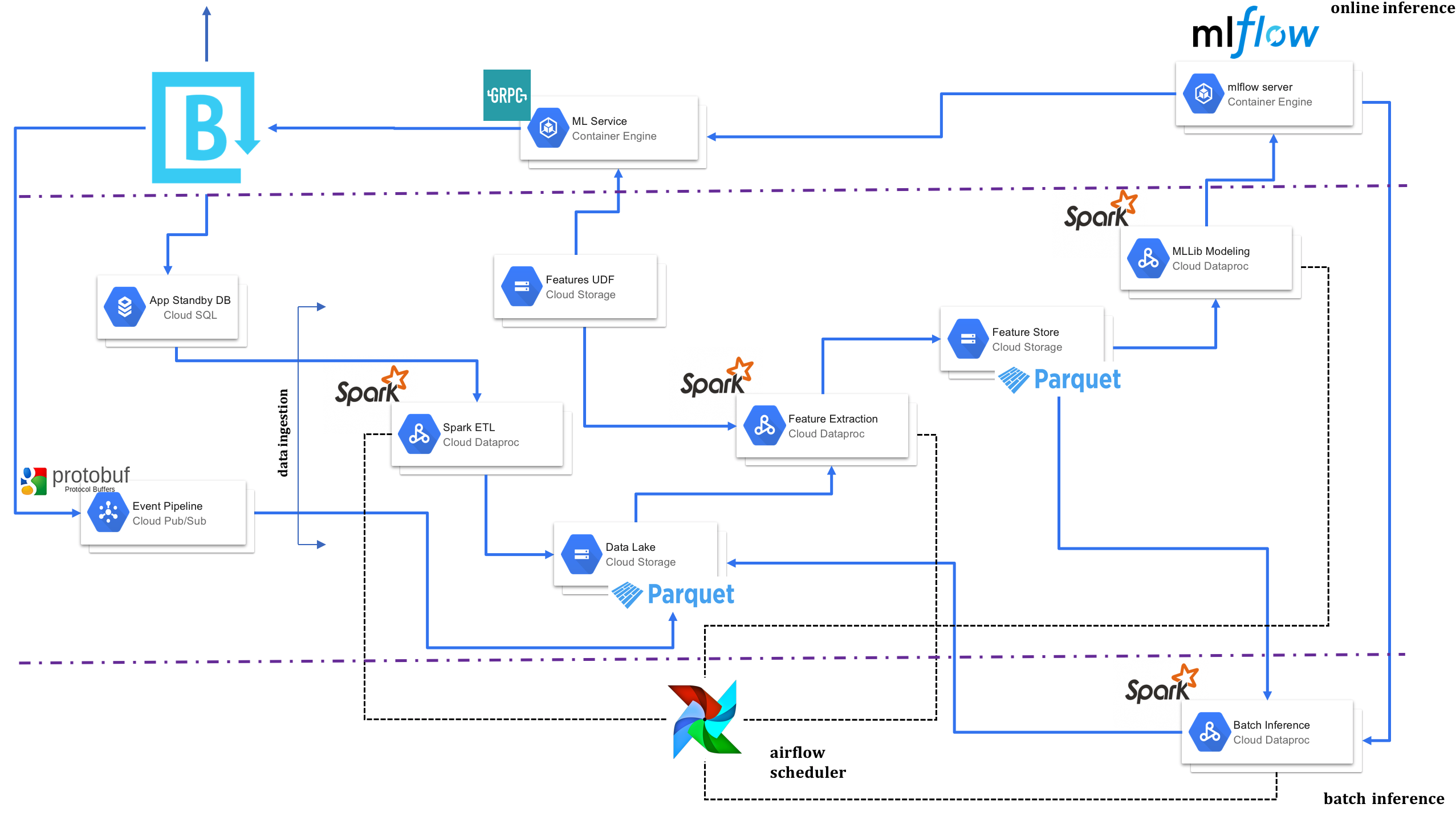
An Overview of the ML Architecture
As shown in the picture below, the transactional data and events from the Brandfolder platform are first pruned using an Extract Transform Load (ETL) procedure using Spark on Dataproc and stored as partitioned parquet⁴ files (with partitioning mainly done on year, month and day columns) in GCS, which serves as the data lake. ML features are then extracted from the data stored in GCS using custom written user defined functions (UDF’s) for each type of feature. The features so extracted using Spark are stored in a global feature store. This feature store is also hosted on GCS in partitioned parquet format as with the ETL’d data. Any combination of the features stored in the feature store serve as input in building ML models that serve different ML use cases. MLLib libraries in Spark are currently used to build out the first ML use cases. Model parameters, metrics and artifacts of different model experiments are then logged to a mlflow server endpoint that is hosted on Kubernetes. mlflow serves as the model versioning and serve mechanism. The model with the best metrics is chosen to score new data using the mlflow clients in both batch and real time modes. A gRPC⁵ ML service is then built for each use case, which takes in real time data, extracts features using the feature UDF’s, uses the model served from mlflow to score the features and finally returns back the scored result as a response to the client calling the ML service. In the rest of this blog we go into specifics of some parts of this architecture.
Data Lake, File Structure, and File Format : GCS serves as the data lake where all the data from both the ETL Spark jobs as well as the pipeline archiver jobs end up storing the data for analytics. Furthermore, this data is stored as partitioned parquet files with the number of parquet files in each partition set to a multiple of the number of total worker cores in the Dataproc cluster (we use a 64 file repartitioning before writing the partitioned parquet files for a 4 workers with 4 cores each configuration). Storing the data as partitioned parquet files, which are in compressed columnar storage format, serves well for optimal analytical processing with Spark.
One Tool, Many Uses: Apache Spark in the above architecture is used for ETL’ing the data from the applications, extracting features from the tables in the data lake as well as for building machine learning models using the extracted features. Spark is also used in the ML gRPC service wherein the mlflow model is pulled down as a Spark user defined function (UDF) to score the incoming data. The mlflow model artifact uses the Spark flavor that saves a pipeline object, which incorporates the transformation of features like documents to tokens and tokens to word2vec etc… It’s also worthwhile to mention that the indices of the data split to training and test sets are also saved to GCS so as to enable revisiting in case of need for further investigation. Furthermore, during the model development cycle, we use the open source Zeppelin Notebooks with Spark interpreter so as to iterate on algorithms before productizing them.
Feature UDF Artifacts: Functions that are used to extract features are stored as Spark UDF’s in GCS. This serves the dual purpose of extraction of features in the batch world as well as for deriving features from a new asset for scoring in the online stage. As and when new types of features for modeling are engineered, the data scientist packages them as Spark UDF functions and adds them to the UDF artifact store.
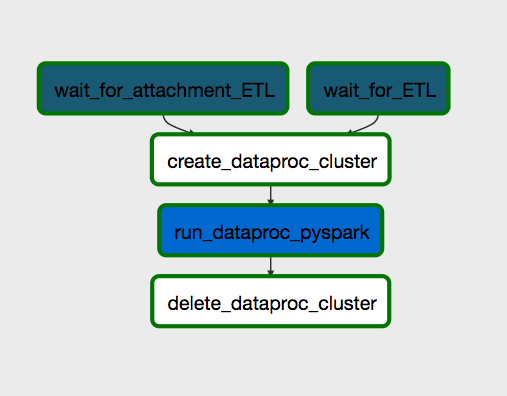
Scheduling the Batch Jobs using Airflow⁶: Google Cloud Composer (Airflow) is used to schedule the different batch Spark jobs. Airflow allows for scheduling jobs using Directed Acyclic Graphs (DAG’s) wherein the logic of execution of jobs can be encoded in a structured format. An example of a DAG is shown below, where a job with three stages is triggered only if two other jobs have completed:
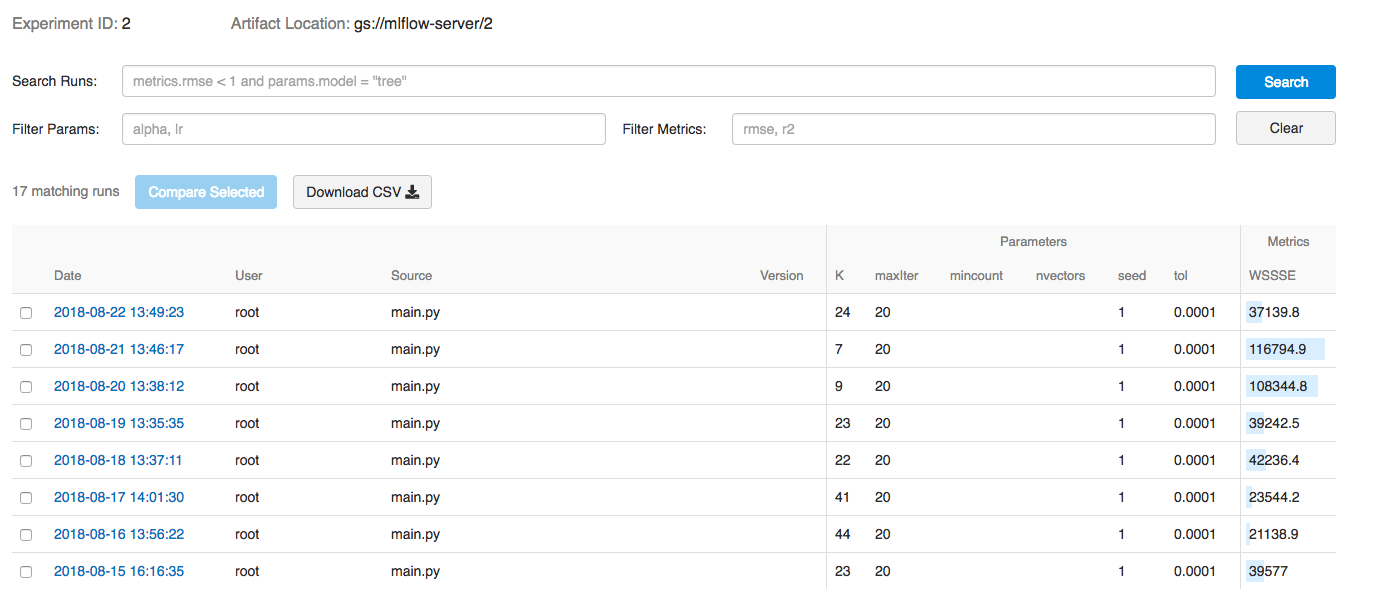
ML Model Parameters, Metrics, and Artifacts: mlflow serves as the platform for logging model parameters, metrics and artifacts for each run of the model. The picture below shows the mlflow board for a particular model which has been run on a daily basis (the data version for each model run is the historical data until the time the model has been run). This makes it easy to choose a version of the model to deploy (from a myriad of runs), which may be based on the model metrics and the time the model was run. mlflow makes it easy to compare the different model runs, thus making it really easy to choose the model to be deployed. Furthermore, the artifacts from each model run is saved by mlflow to GCS and can be pulled down in the model serving phase as is described in the next paragraph.
Serving ML Models using mlflow: A model with the best metrics is chosen to be served to score the new data that the ML service receives. To this end the guid of the experiment that is chosen to be deployed from the mlflow server is passed on to the ML service. The mlflow client in the service pulls down this model and uses it to transform and score the new data to generate a prediction column. A snippet of this procedure is shown below:
import mlflow
mlflow.set_tracking_uri("http://mlserver.com")
# pulling down the mlflow model with the run_id
model = mlflow.spark.load_model("model", run_id='92fc7a8324f24371963f66c9ed901748')
# score newdata_df using model and create a prediction column
scored_df = model.transform(newdata_df).select('prediction')
Quick Note on Language, CI/CD, and Artifact Repository: It’s python all the way in the above ML architecture. More specifically, the python API for Spark (pyspark) is used for all Spark jobs. Airflow DAG’s are natively written in python and mlflow libraries are in python as well. Usual python libraries like numpy, pandas, scikit-learn and matplotlib are leveraged heavily in various parts of the project. The ML gRPC service is also written in python (a Go gateway wrapper is used if the gRPC service needs to support a REST interface). CircleCI is used to build, test and deploy the artifacts when changes are committed to Github. The artifacts i.e. the python main file and additional files are pushed to GCS that serves as the artifact repository.
Concluding Remarks
In the above we have described a first cut ML platform that enables us to quickly iterate through the different use cases and release data driven product features into the Brandfolder platform. This also helps us modularize various functions in the platform, like for example a data scientist can focus on developing the feature UDF’s, writing the feature extraction scripts, develop models and deploy them to mlflow server for the use case of interest.
Next steps in our iterations include monitoring prediction of the live model (to make sure that it behaves as we expect in production), releasing new models through shadowing (i.e. running beside live model to see how it performs, but not running in production) and also progressively rolling out new models using A/B testing of new and old model performances as well as incorporating user feedback. There is also a streaming use case, wherein we plan to use Spark’s structured streaming to compute statistics as data arrives and trigger anomalies if the statistic deviates from norm (which is maintained as state). We are also working towards deploying deep neural network models developed for unstructured data using TensorFlow⁷ on GCP by employing the same architecture described above. Stay tuned for our adventures on those projects in a future blog post.
References [1] https://spark.apache.org/ [2] https://mlflow.org/ [3] https://cloud.google.com/ [4] https://parquet.apache.org/ [5] https://grpc.io/ [6] https://airflow.apache.org/ [7] https://www.tensorflow.org/