As Brandfolder has grown dramatically in size, so has the usage of the Brandfolder API. This is a natural consequence of a product growing at an exponential rate, especially one that relies on both the private and public APIs for all actions within the web app itself and by external developers. With close to 60 in-house integrations, countless third-party integrations and our webapp all utilizing the API at various rates and frequencies, Brandfolder is forced to pay the price in the form of infrastructure and processing costs. With the predicted rate of usage growth for the foreseeable future, we had to find a solution to help scale API use. Building webhook service met all of our needs, and additionally gave us the opportunity to keep our API modern, since webhooks are a tool of many developer-friendly APIs.
The Problem - Expanded
A common problem that occurs with the vast majority of API services is the cost of polling. Polling refers to an external service sending a request to a public API endpoint and essentially asking, “has anything that I care about changed since I last asked?” We see polling intervals set anywhere from sending requests every second to sending requests every few days. While this may seem pretty simple, these actions become very complex and can be bucketed into the following categories: wasted computing and client complexity.
Wasted computing:
-
When a request is sent, Brandfolder processes the request and returns relevant results. Depending on the amount of content in a Brandfolder, a request to
https://brandfolder.com/api/v4/brandfolders/{bf_id}/assetscan contain a hefty response. If?fields=cdn_url&include=section,tags,custom_fieldsis appended to the end can cause significant processing delays and will require extra processing by the client. - When results from Brandfolder are returned, the client then needs to process these results and make a determination about what has changed since last request and throwing away anything that is still the same.
- More often than not, depending on the frequency of polling requests, the result is “nothing has changed”. When this happens, all of the processing is essentially wasted.
Client complexity:
- Oftentimes requests are formatted only “mostly” correctly. For those who don’t work with our API on a regular basis, there is a good chance that the request made is overly complicated for the information the integration needs - this leads to slower response times and increased processing time.
- The integration client needs to keep a record of the results of the previous poll and diff them against the new request. Integrations with light usage and not a lot of assets/attachments in a Brandfolder are not a problem, but once interactions begin to happen with heavily used Brandfolders, another bottleneck is introduced and imposed upon the destination system.
- Provided the above, without webhooks, both Brandfolder and external systems need to have the ability to manage scale which can be a tough ask for external systems.
Webhooks
If polling is asking for data and comparing what is different, what are webhooks? Webhooks are similar to push notifications to your service. Quite simply, you can subscribe to one or many webhooks using the webhook API. When an event occurs in Brandfolder that matches a supported webhook event, this event is published and passed to the end user’s defined callback url.
The cool part about this is when you get a webhook, you know something has changed. You can then ask for focused data based on the data provided by the webhook. This can help to drastically simplify the request and processing, as you can specify to only get back the data you care about and, as with the current implementation of our webhook service, only request data on a single asset.
An example of this can be seen in the Brandfolder implementation. In our service, clients receive a webhook when an action occurs on an asset in the Brandfolder they have subscribed to. In this case, instead of requesting data on 10,000 assets (for example) and comparing the data returned to the results of the previous poll, client applications now only have to ask for a single asset’s data and act accordingly.
Design Considerations
Sitting down at the whiteboard for the first time, we had to determine what scope we wanted our webhook service to manage. Actions can occur at any level within the system - within an organization, a brandfolder, an asset or an attachment. (For those that may not be familiar with how the Brandfolder system is structured, view our API Docs for a description of how everything is related.)
The relationship between all of these levels can become pretty complicated if you try to build for all at once, versus taking a more iterative approach. For this reason, we decided to begin by only implementing asset events. By limiting this, we were able to get real world feedback on the service that will assist us in building future event types. With that key design piece out of the way, we could move on to the following considerations:
- What services are at our disposal to create events and POST event data to a client’s callback url?
- How should we handle processing delays, out of order webhooks and potential duplicate events?
- What is the most effective way of managing security for this service?
- How can we keep both read and write queries efficient enough to not be an additional bottleneck?
- What issues do we foresee with scaling the service? Where are the bottlenecks?
The Brandfolder Implementation
A lot of planning went into how we wanted to solve the above considerations. From the beginning we planned to build the service in Python with the webhook API as a Flask application. Many of our current integrations are designed this way. This allows for easy extension of functionality through the plethora of modules built for Python.
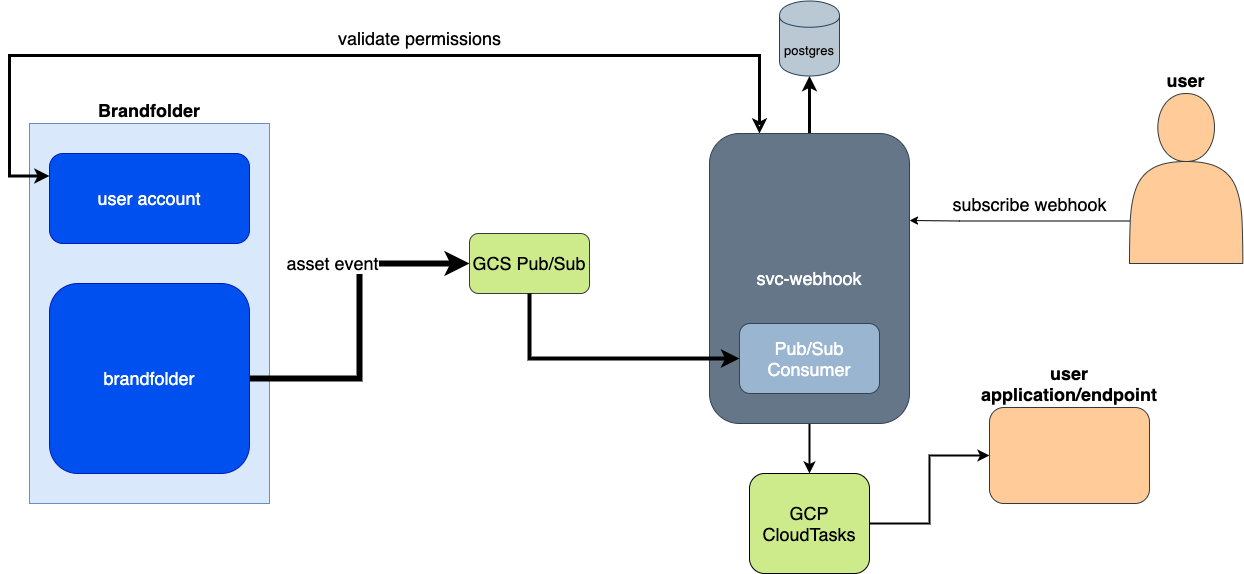
Architecture
Google Cloud Pub/Sub
We determined that the primary objective of the webhook service was to limit the polling on our API, so we came to the conclusion that internal events should be published directly from the asset service. A traditional publisher/subscriber (pubsub) model solves this problem for us - internal events are published to Pub/Sub and the webhook service subscribes to those messages. For other services and use cases, Brandfolder already leverages Google Cloud Pub/Sub, so for consistency, it made sense to expand the events already being published.
Google Cloud-Tasks
Having solved the challenge of publishing events, we needed to tackle the issue of passing data along to the resulting callback url. With Python we could lean on the requests module, but doing so would force us to build and maintain the logic for deduplicating tasks and building a backoff strategy for requests that error. We ultimately decided to, once again, rely on Google Cloud Services and built the webhook service to leverage Google Cloud-Tasks.
Google Cloud-Tasks was a great decision because it comes with a lot of the infrastructure that we needed already built in. When configuring the service, we can provide a custom backoff strategy for errors, or rely on the default. This means that anytime we attempt to send a POST request to a subscriber’s callback url and it returns anything other than a 200 or 301, Cloud-Tasks will consider that an error and put the request back in the queue to try again. After enough time has passed, if we still cannot make a successful request, the task is dropped.
Additionally, Cloud-Tasks can also manage deduplication of events. With the number or workers processing incoming pubsub messages, it is very likely that some message will get processed multiple times (Pub/Sub promises “at least once delivery”). To combat this, we leverage the ability to generate a task name that Cloud-Tasks offers where it doesn’t allow for an event with an already seen name to be processed within a certain amount of time. To accomplish this, we can use this simple and nifty bit of code:
task = {
'name': name,
'http_request': {
'url': data['callback_url'],
'body': encode_payload(data['payload']),
'headers': {
'Content-Type': 'application/json',
**(headers or {})
}
}
}
task_id = client.create_task(parent=parent,
task=task)
name in the task dictionary is an MD5 hash of concatenated values from the asset.[event] payload. During create_task() the task['name'] is analyzed by Cloud-Tasks to determine if it has seen that task name previously. If so, it sends back a 400 and the event is simply discarded.
With that, Cloud-Tasks allows us to solve many infrastructure challenges pretty easily.
Security
Building security models can be quite the undertaking, especially as a service grows and expands in functionality. Security implementations can become very complex, very fast. Additionally, Brandfolder already has very robust security and the only real purpose of svc-webhook is to forward along data that it received from and authorized by Brandfolder. With that already in place, there was no use in reinventing the wheel.
To manage security, our implementation approached the challenge in the following ways:
- When a client requests to subscribe to an
asset.[event]we require thebrandfolder_keyfor the Brandfolder they are subscribing to, and the user’s uniqueapi_key. We then run a quick check to ensure thatapi_keycan access data in that particular Brandfolder. If all is good, a webhook is created and we are on our way. - When an event occurs that matches a webhook subscription, we grab the
api_keyused when creating the subscription and run the same authorization check to confirm that user still has access. If all is good, we continue to forward the data to the designated callback url. If not, we automatically deactivate the webhook. - To avoid running auth checks too frequently, we cache the result of all checks for 30 minutes.
- To resolve the obvious concern of “what if something happens during the 30 minute caching period you mentioned above?”, we greatly limit the amount of data we forward along, so that anyone that could possibly intercept the webhook payload cannot take any action on it, unless they have the appropriate API key (if your Brandfolder API key has been compromised, just reach out to us and we can help with that).
The payload is as follows:
{
"data": {
"attributes": {
"key": unique_asset_identifier,
"eventTime": event_timestamp (from Brandfolder),
"event": ["create", "update", "delete"],
"brandfolder_key": unique_brandfolder_identifier,
"organization_key": unique_organization_identifier
},
"webhook_id": webhook_id
}
With this payload, you can see what type of event occurred (ex. asset.create) and know that an asset was created in your Brandfolder. You also can see the time the asset was created, and the unique identifier that Brandfolder gives it. Other than that, there is no actionable data included. You must send an authorized request to Brandfolder to get data that is actionable.
Scaling
With Google Pub/Sub and Google Cloud-Tasks in our arsenal, a lot of scaling concerns are managed for us. Being the giant that it is, we can be reasonably certain that processing of events in Pub/Sub and sending requests to callback urls from Cloud-Tasks should not run in to scaling issues. The potential bottleneck comes in the processing of messages received from Pub/Sub. To combat this, we took an “order of operations” approach when determining if a subscription exists or not. We look at the data available from the webhook and determine an order of priority for checking a webhook that is both fast and has the opportunity to remove a lot of noise generated from from Pub/Sub messages that don’t have an associated webhook.
Our order of operations:
- Is the event type supported? This almost always returns a True but if ever Brandfolder begins to publish events that svc-webhook isn’t prepared for, this is a very quick check to simply ignore them.
- Is there a subscription for the Brandfolder the event was generated from and for that event type?
- For each subscription, are permissions still valid? If not, deactivate the webhook so it isn’t returned next time around. If yes, cache that result so that we don’t keep running authorization checks for active Brandfolders.
From that point, we can reasonably scale our workers to meet additional scaling needs.
A Use Case
A client wants to create and update files in the media library of a third party service. Without webhooks, they have to ask the Brandfolder API for all assets in a Brandfolder - potentially scoped to only a section or a collection (again, for more detail on the structure of Brandfolder, see our API docs). Depending on the amount of data required to conduct the media sync, the client application will need to either make multiple requests per asset that matches a set criteria every time the job runs or they will have to deal with potentially slow responses because of the amount of extra data they request. This can limit the number of API calls but, depending on the size of the Brandfolder, can really slow down response times for data that will very likely be ignored anyway.
When the data is returned, they then must compare the response to information stored on previous job runs to determine which assets are new, which have been updated, and which have not changed at all. Once processed, they make as many API requests as needed to the third-party service to create all needed assets and update any that have changed.
Enter webhooks. From the above example our client application is interested in asset.create and asset.update events. Once they have subscribed to these events and set up a webhook receiver (an endpoint they create to accept POST requests from the webhook service), they will begin to receive these events individually to process. The workflow then changes to the following:
- Receive event.
- Determine if it is a create or update event.
- If create: request only the relevant data for that single asset from Brandfolder.
- If update: look up previous instance of that single asset, request asset data from Brandfolder and compare to find the differences.
- Format and send API request to third-party based on the above information.
As you can see, that is a much simpler workflow and helps avoid the bottlenecks that come with processing large amounts of data and maintaining state for all.
Some Additional Details
API Consistency:
With the webhooks service coming in to existence to help simplify the usage of the Brandfolder API, we assumed that many of those that will use the service have some level of familiarity with our API. For that reason we wanted to ensure that requests and responses were as similar as possible. Brandfolder API V4 is based on the JSON API spec.
Additionally, the design of the Brandfolder API has worked well for years with the ability to adhere to contracted responses that will not break client applications on updates, so svc-webhook follows the same structure. After all, there is nothing more frustrating than coming in to work to find out your application is broken after some API you use has an update and now your application starts throwing KeyErrors everywhere…
Monitoring and telemetry data:
For the last couple of years we have been relying on Datadog and statsd to track telemetry data from our applications. This service is quite simple to use and has been invaluable. In Python, you can add a couple of lines of code that can give you very useful information:
from datadog import statsd
def process_message(message): # example function you want to track
statsd.increment('message.process.count')
try:
# Do some stuff here
statsd.increment('message.process.success', tags= [f'event_type: {event_type}'])
except:
statsd.increment('message.process.failure', tags=['cause: some_reason', f'event_type:{event_type}'])
The above will add a record for message count, which we will count in Datadog. Depending on success or failure of the function, we will increment the respective metric. The tags can help us determine what types of events we are processing most and the most common areas one might fail to process fully.
For our reporting we like to track some additional metrics than just counts. Additionally, we leverage:
- message processing time
- queue depth in GCS CloudTasks
- database connections
- publishing latency from Brandfolder
All of the above help to paint a very useful picture of how the service is performing.
Data on the Service
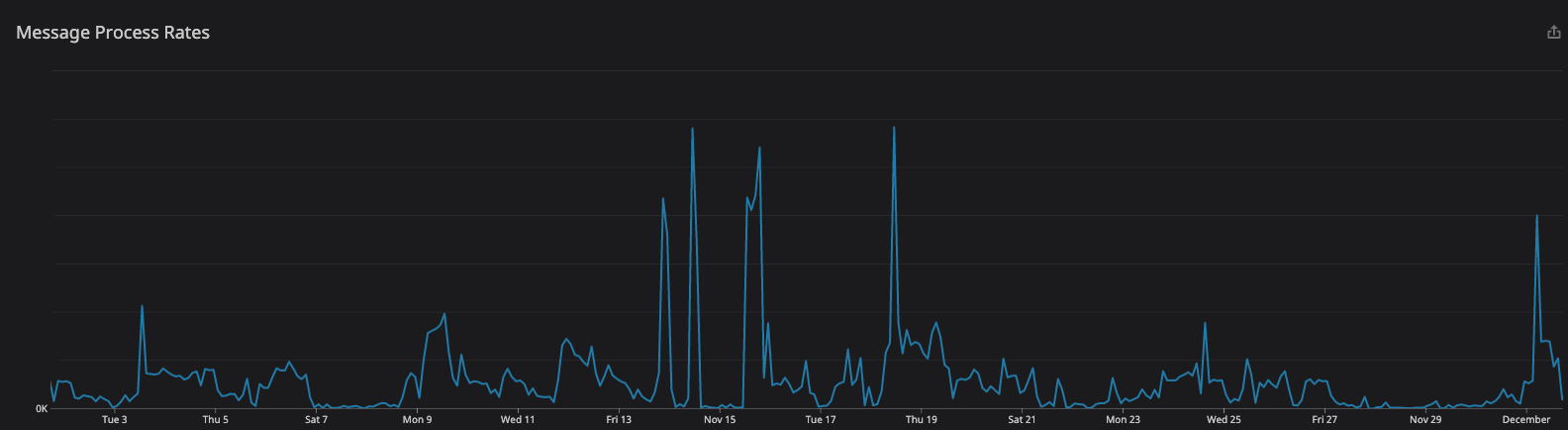
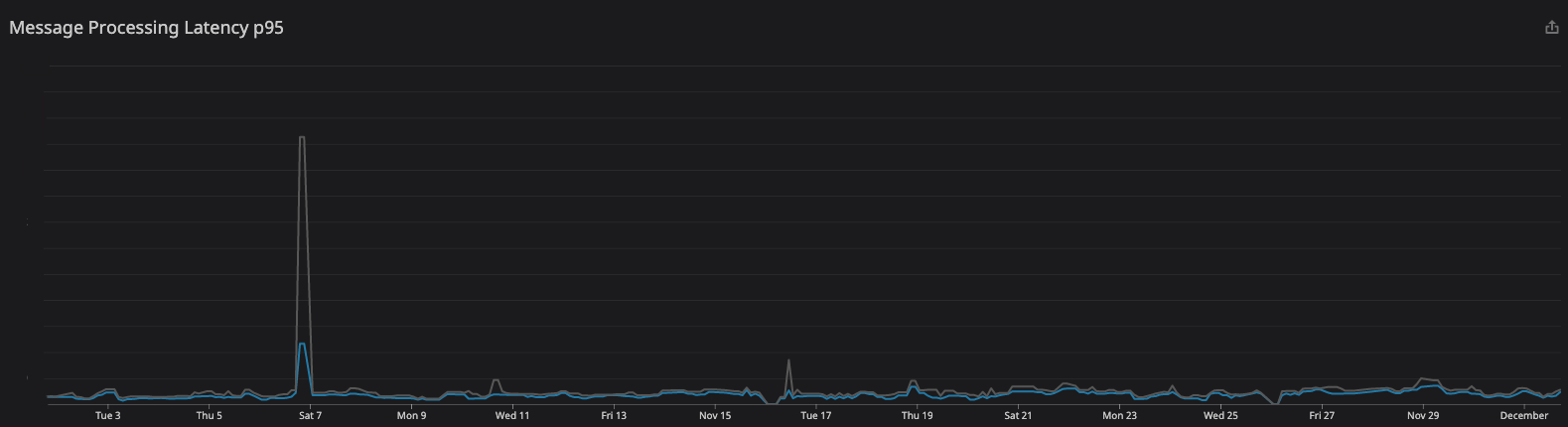
After 10 months of processing events, we have seen:
- Message Processing Success Rate: 99.9999%
- Traffic Bursts: +8500%
- Avg. Message Processing Latency: < 200ms
Conclusion
Building a webhook service has ultimately been a great thing for Brandfolder and we are seeing it utilized more and more by the clients that rely heavily on our API. Not only does our webhook service limit the processing by both Brandfolder and client applications, but it helps provide much more real-time data that is much faster to digest. As more clients adopt its usage, the service will continue to grow and improve. If you have questions about using the service or suggestions on how to improve it, we would love to hear from you!